When dealing with large volumes of data on Kafka, every incoming message adds load to the network and client applications. The Lightstreamer Kafka Connector introduces an efficient filtering mechanism, ensuring that only relevant messages are forwarded to clients based on their specific requests, rather than indiscriminately transmitting the entire data stream of a topic.
This approach is particularly advantageous for end-user clients—such as mobile or web applications—where bandwidth, latency, and resource consumption are critical, as opposed to backend systems designed to consume and process large data sets.
Key Benefits of This Approach
- Reduced Network Traffic – Prevents network congestion by sending only necessary data, improving overall performance.
- Optimized Client Efficiency – Clients receive only what they need, reducing computational load and eliminating the need for client-side filtering.
- Improved Scalability – Server-side filtering optimizes resource usage, allowing more clients to be handled without performance degradation.
- Lower Latency – Faster data delivery since clients don’t have to receive, process, and discard irrelevant messages.
This functionality is highly valuable in data-intensive scenarios such as real-time analytics, market monitoring, and IoT applications, where each client requires a specific subset of information.
For detailed instructions on how to define filtering rules with the Lightstreamer Kafka Connector, please refer to the official documentation: Lightstreamer Kafka Connector Filtering Documentation. That provides step-by-step explanations on how to configure filtering criteria, ensuring that only the relevant messages are delivered to clients based on their subscription parameters.

In the rest of this blog post, we will explore how the Lightstreamer Kafka Connector performs under targeted load tests, assessing its ability to scale in increasingly complex filtering scenarios.
Our Test Approach
The tests progress through several phases, each designed to increase the computational demands of the filtering process. We start with a basic scenario involving:
- A single client, responsible for collecting data based on specific selection criteria and measuring the latency of the received messages.
- A dedicated Kafka message producer used for latency measurement (running on the same machine as the client to avoid clock synchronization issues).
- A set of Kafka producers generating background load.
- Kafka messages with string keys and a simple JSON object as the payload.
- The client subscribes to receive only messages with a specific key value, selected from a pool of 40 possible values.
The tests then progress to more complex message structures, where each Kafka message uses a complex JSON object as the key, and the filtering condition targets a specific field within a deeply nested structure.
Finally, we conclude with a comprehensive test scenario that combines high message throughput with a large number of concurrent clients, simulating a more realistic, production-scale workload.

The tests also compare different consumption and deserialization strategies in the Lightstreamer Kafka Connector based on the number of concurrent threads. Specifically, we evaluate:
- A single-threaded approach.
- A multi-threaded approach, where the number of threads matches the number of partitions defined for the Kafka topic.
These consumption strategies can be configured via the record.consume.with.num.threads and record.consume.with.order.strategy parameters, allowing fine-grained control over how messages are processed. For more details, refer to the official documentation: Lightstreamer Kafka Connector Documentation
This methodology ensures a thorough assessment of how the Lightstreamer Kafka Connector performs under various filtering and scaling conditions.
Full details regarding the infrastructure, instance types, and tooling used throughout the testing process are provided in the ‘Setup the Environment’ section later in this post.
The Basic Scenario
In the basic scenario the messages produced and sent to Kafka have a key serialized as a string of 500 alphabetic characters. Each message sent to the topic has a key randomly selected from a pool of 40 possible values and the client subscribes to receive messages with a specific, predetermined key value. The message payload is a serialized JSON object with the following simple schema:
{
"title": "TestObj",
"type": "object",
"properties": {
"timestamp": { "type": "string" },
"fstValue": { "type": "string" },
"sndValue": { "type": "string" },
"intNum": { "type": "integer" }
},
"required": ["timestamp", "fstValue", "sndValue", "intNum"]
}In this test scenario, we evaluated the Lightstreamer Kafka Connector under increasingly demanding workloads, we pushed the boundaries with production rates of 64,000, 80,000, and finally 100,000 messages per second. The kafka topic used has 4 partitions and so the tests were performed using both configurations of the connector:
- Single-threaded mode, where messages are processed sequentially.
- Multi-threaded mode, where 4 threads concurrently deserialize and filter incoming records.
Key Findings
- Sustained High Throughput – The connector successfully handled up to 100,000 messages per second, demonstrating its capability to operate under extreme conditions.
- Minimal Latency – In all test cases, message reception latency remained consistently below 10 milliseconds, ensuring near-instantaneous data delivery.
These results confirm that the Lightstreamer Kafka Connector is highly optimized for real-time data streaming, capable of managing heavy traffic loads without introducing processing delays.
| threads | mono | 4 | mono | 4 | mono | 4 |
|---|---|---|---|---|---|---|
| Number of messages per second produced | 64K | 64K | 80K | 80K | 100K | 100K |
| Number of messages per second sent to the single client | 1,600 | 1,600 | 2,000 | 2,000 | 2,640 | 2,640 |
| Outbound throughput (Mbit/s) | 4.0 | 4.0 | 5.0 | 5.0 | 6.4 | 6.4 |
| Mean latency (ms) | 4 | 5 | 6 | 7 | 10 | 10 |
| Lightstreamer server cpu | 10% | 14% | 14% | 18% | 16% | 21% |
Below are some examples of the tools used to monitor and collect test results, specifically a couple of screenshots of the Lightstreamer server monitoring dashboard, which allows for real-time observation of data flow consistency and congruence with the current test scenario, and the output from the client’s statistics calculator, which reports the detected latencies.
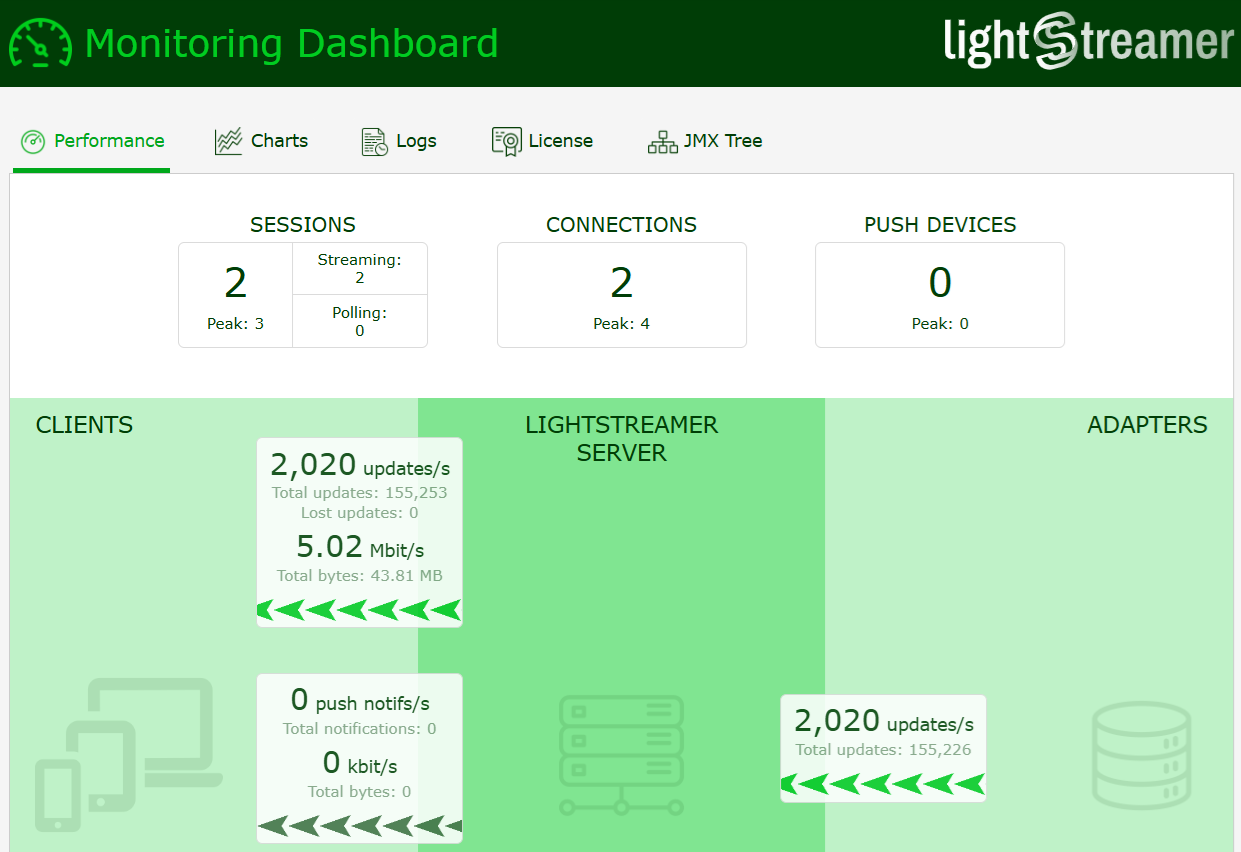
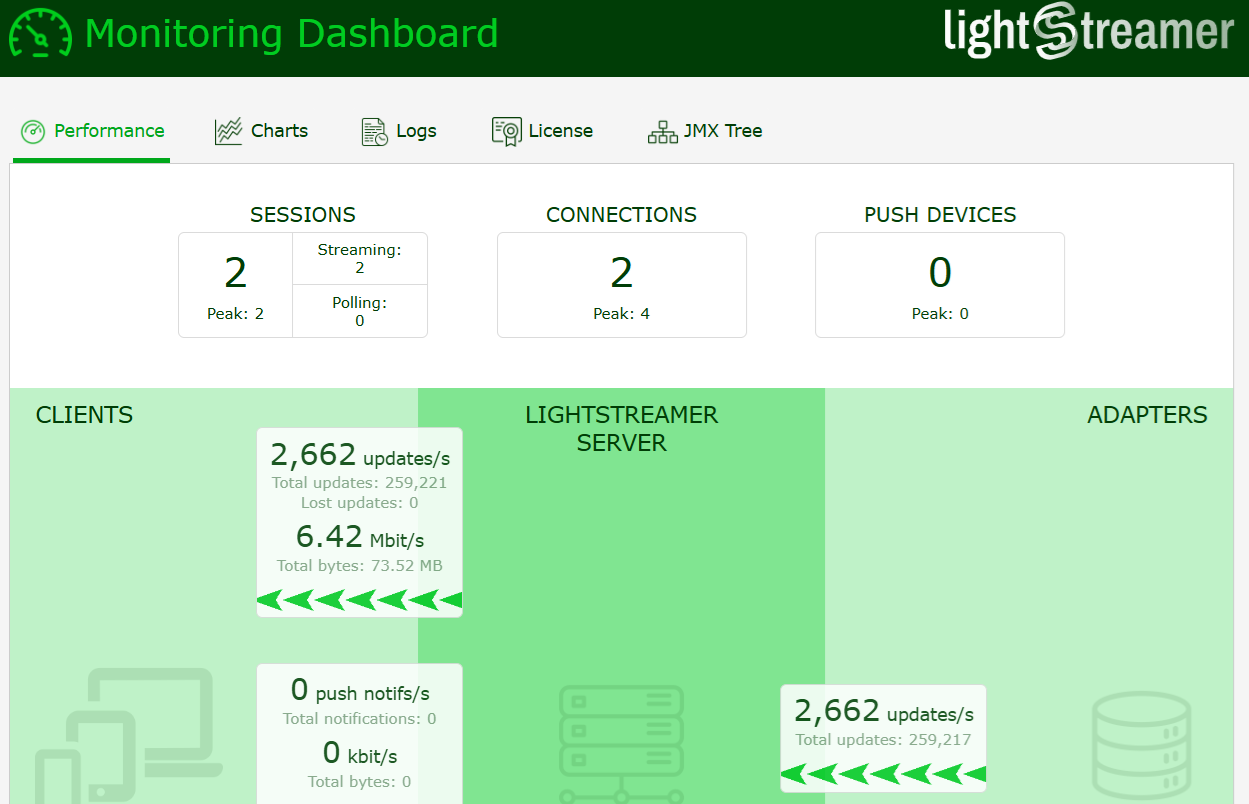
14:46:22.462 [pool-2-thread-1] INFO com.lightstreamer.StatisticsManager - Generating latency report...
14:46:22.463 [pool-2-thread-1] INFO com.lightstreamer.StatisticsManager -
Test Duration: 0 Hours 7 minutes and 29 seconds
Number of samples: 450
Min = 2 ms
Mean = 4 ms - Standard Deviation = 4 ms
Max = 73 ms
25th Percentile = 3 ms
50th Percentile = 4 ms
75th Percentile = 5 ms
90th Percentile = 6 ms
95th Percentile = 7 ms
98th Percentile = 10 ms
Min
0002 - 0011 ********************|
0011 - 0020 |
0020 - 0029
0029 - 0038 |
0038 - 0047
0047 - 0056
0056 - 0065
0065 - 0074 |
Max
ZOOM
Min
0002 - 0003 ******************|
0003 - 0004 ***************|
0004 - 0005 ********************|
0005 - 0006 ********|
0006 - 0007
90th percentileOne final observation from this test scenario is that increasing the number of threads for consuming messages from the Kafka topic did not provide significant benefits. In fact, we observed a general increase in CPU usage and even a slight rise in latency. This suggests that, under these specific conditions, a single-threaded approach is already efficient enough to handle the load without unnecessary overhead. However, the real test comes when the computational complexity of filtering increases. Next, we will analyze a scenario where the filtering logic requires more intensive processing and evaluate whether multi-threading can provide a clear advantage in those conditions.
Increasing Filtering Complexity: A More Challenging Test
To push the filtering capabilities of the Lightstreamer Kafka Connector further, we designed a more complex scenario by increasing the complexity of the message keys sent to Kafka. Instead of using a simple string as the key, we introduced a JSON object with multiple and also complex fields, making the filtering process more computationally demanding. In this test, the selection criterion was based on a specific field within the JSON object, requiring the connector to inspect and evaluate a nested structure rather than performing a straightforward string match. The schema of the JSON object used as the message key is as follows:
{
"title": "KeyObj",
"type": "object",
"properties": {
"timestamp": {
"type": "string"
},
"nameId": {
"type": "string"
},
"sndValue": {
"type": "string"
},
"intNum": {
"type": "integer"
},
"names": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": [
"timestamp",
"nameId",
"sndValue",
"intNum",
"names"
]
}In this scenario, the client subscribes to a filtered data stream using a specific selection criterion: the 999th element of the names field, an array of 1024 elements, within the JSON key must match a particular value. This significantly increases the computational complexity of the filtering process. Unlike the previous test, where simple key-based selection was sufficient, this scenario requires deep inspection of structured data, making filtering far more resource-intensive. The message payload is the same as in the previous scenario.
As a result, the ability to utilize multiple threads for consuming and processing messages becomes a critical factor. The workload is now substantial enough that parallel processing can provide a meaningful performance boost.
Below are the results obtained from this experiment.
| threads | mono | 4 | mono | 4 | mono | 4 | mono | 4 |
|---|---|---|---|---|---|---|---|---|
| Number of messages per second produced | 2K | 2K | 4K | 4K | 6K | 6K | x | 10K |
| Number of messages per second sent to the client | 50 | 50 | 100 | 100 | 150 | 150 | x | 250 |
| Outbound throughput (Mbit/s) | 0.16 | 0.16 | 0.32 | 0.32 | 0.48 | 0.48 | x | 0.8 |
| Mean latency (ms) | 5 | 6 | 6 | 6 | >100 | 7 | x | 8 |
| Lightstreamer server cpu | 10% | 15% | 18% | 23% | 25% | 28% | x | 50% |
Key Findings
The single-threaded configuration performs well until the CPU usage of the Lightstreamer server reaches 25%, which, on a 4-core machine (that is the case of the Lightstreamer instance of our tests), corresponds to fully saturating a single core. This bottleneck occurs at 6,000 messages per second, at which point the system struggles to keep up with the incoming data stream, causing the average latency to spike above 100ms.
In contrast, the multi-threaded configuration with 4 parallel threads distributes the workload across all available cores. As a result, it successfully maintains an average latency below 10ms, even at 10,000 messages per second. This highlights the crucial role of multi-threading in handling computationally expensive filtering tasks under high message throughput.
Here are few results from the tests conducted with a message production rate of 10,000 messages per second.
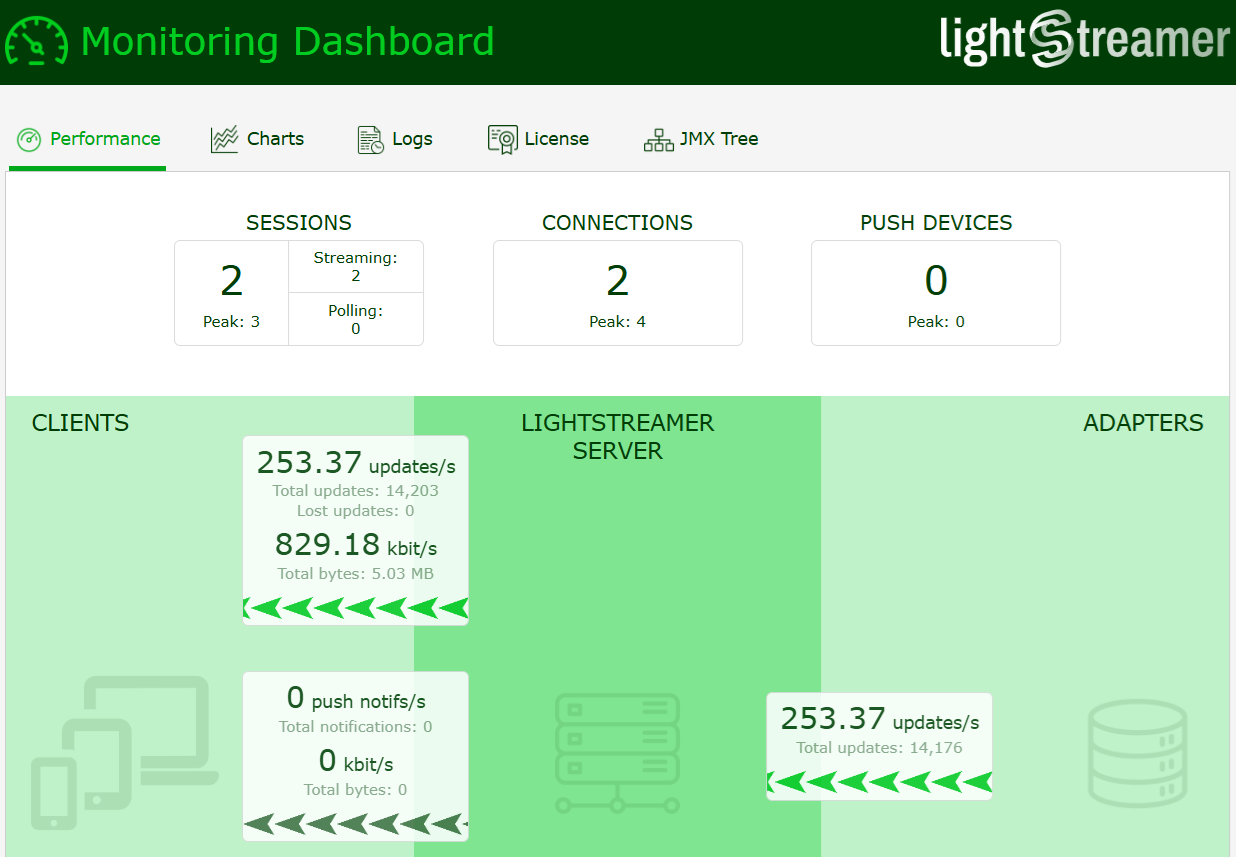
Test Duration: 0 Hours 3 minutes and 11 seconds
Number of samples: 110
Min = 3 ms
Mean = 8 ms - Standard Deviation = 16 ms
Max = 128 ms
25th Percentile = 5 ms
50th Percentile = 6 ms
75th Percentile = 7 ms
90th Percentile = 9 ms
95th Percentile = 12 ms
98th Percentile = 32 ms
Min
0003 - 0019 ********************|
0019 - 0035 |
0035 - 0051
0051 - 0067
0067 - 0083
0083 - 0099
0099 - 0115 |
0115 - 0131 |
Max
ZOOM
Min
0003 - 0004 ******************|
0004 - 0005 ********************|
0005 - 0006 ***********|
0006 - 0007 ***************|
0007 - 0008 ***********|
0008 - 0009 ***|
0009 - 0010
90th percentile
Final Comprehensive Test: Scaling Clients and Message Throughput
To conclude our evaluation, we orchestrated a comprehensive end-to-end test designed to simulate a high-load production environment. This scenario combined a substantial volume of messages produced per second with a significant number of consuming clients. In many respects, the conditions mirrored those of the initial scenario, with the key distinction being the scale of Lightstreamer clients, which in this case reached into the thousands.
Crucially, all messages consumed from the Kafka topic were also expected to be delivered to at least one client, as each active test client established a subscription by randomly selecting one value from the 40 available.
We conducted the tests using multiple cross-combinations, varying:
- The number of concurrent clients from 1,000 to 12,000.
- The Kafka message consumption rate from 2,000 to 16,000 messages per second.
The test is considered a success if latency remains below 100 milliseconds and, more importantly, stays stable over time, meaning there is no backlog or accumulation of delays.
| msgs/s x no. clients | 1K | 2K | 4K | 6K | 8K | 10K | 12K |
|---|---|---|---|---|---|---|---|
| 2K | 3 (1) | 3 (2) | 4 (3) | 8 (4) | 10 (11) | 26 (18) | 48 (40) |
| 4K | 3 (3) | 4 (5) | 6 (6) | 17 (11) | 235 (337) | x | |
| 5K | 3 (4) | 6 (4) | 16 (19) | 24 (37) | x | ||
| 8K | 4 (2) | 8 (8) | 36 (40) | x | |||
| 12K | 4 (1) | 10 (4) | x | ||||
| 16K | 4 (2) | 12 (6) | x |
Performance Insights: Exceptional Efficiency on a Modest EC2 Instance
One of the most remarkable takeaways from this test is the exceptional performance achieved despite the modest size of the EC2 instance used for the Lightstreamer server (c7i.xlarge).
Even under heavy workloads—with thousands of concurrent clients and high outbound message throughput—latency remained impressively low across a wide range of test conditions. The system successfully sustained demanding real-time data delivery while efficiently handling both the Kafka message consumption and the streaming of filtered data to thousands of clients. The few monitoring dashboard screenshots presented below clearly showcase the exceptional scalability of the system, with a total outbound throughput reaching an impressive 1.6 million messages.
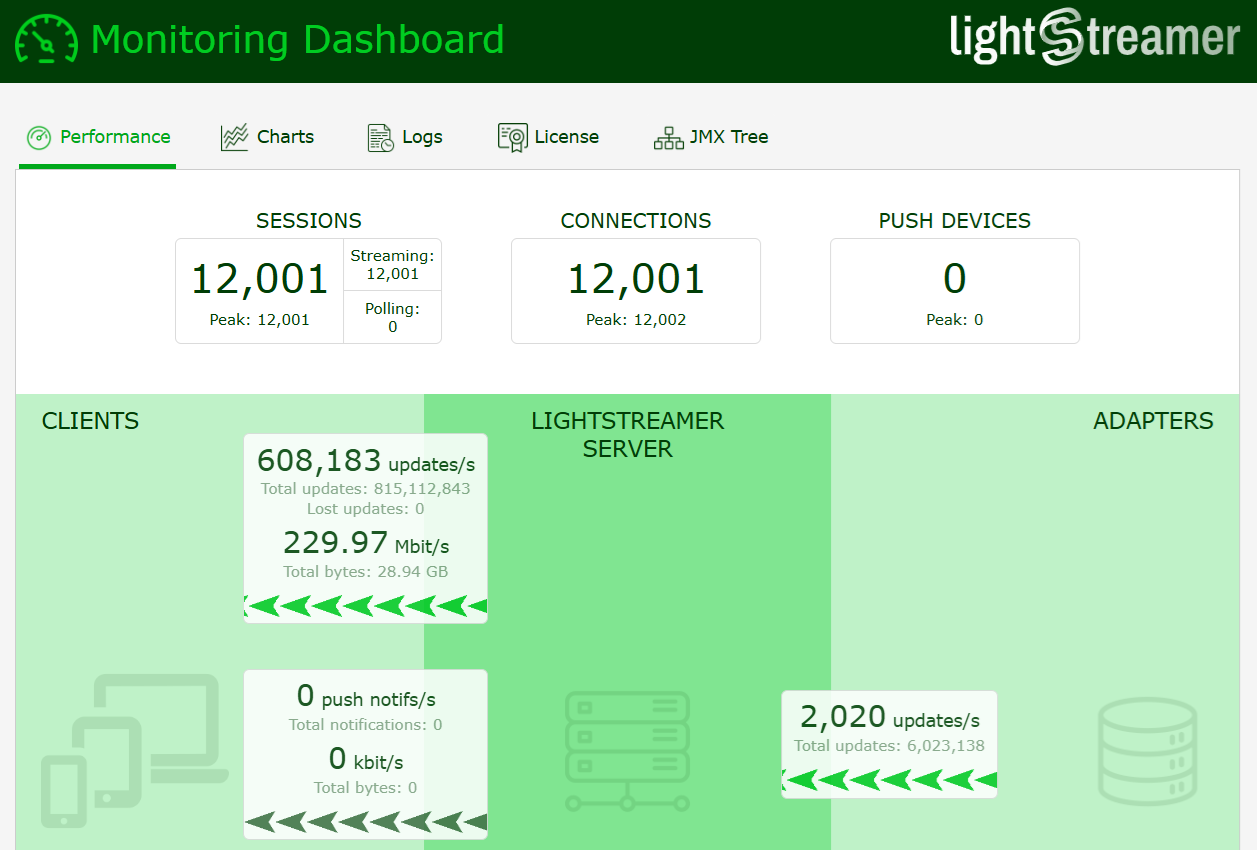
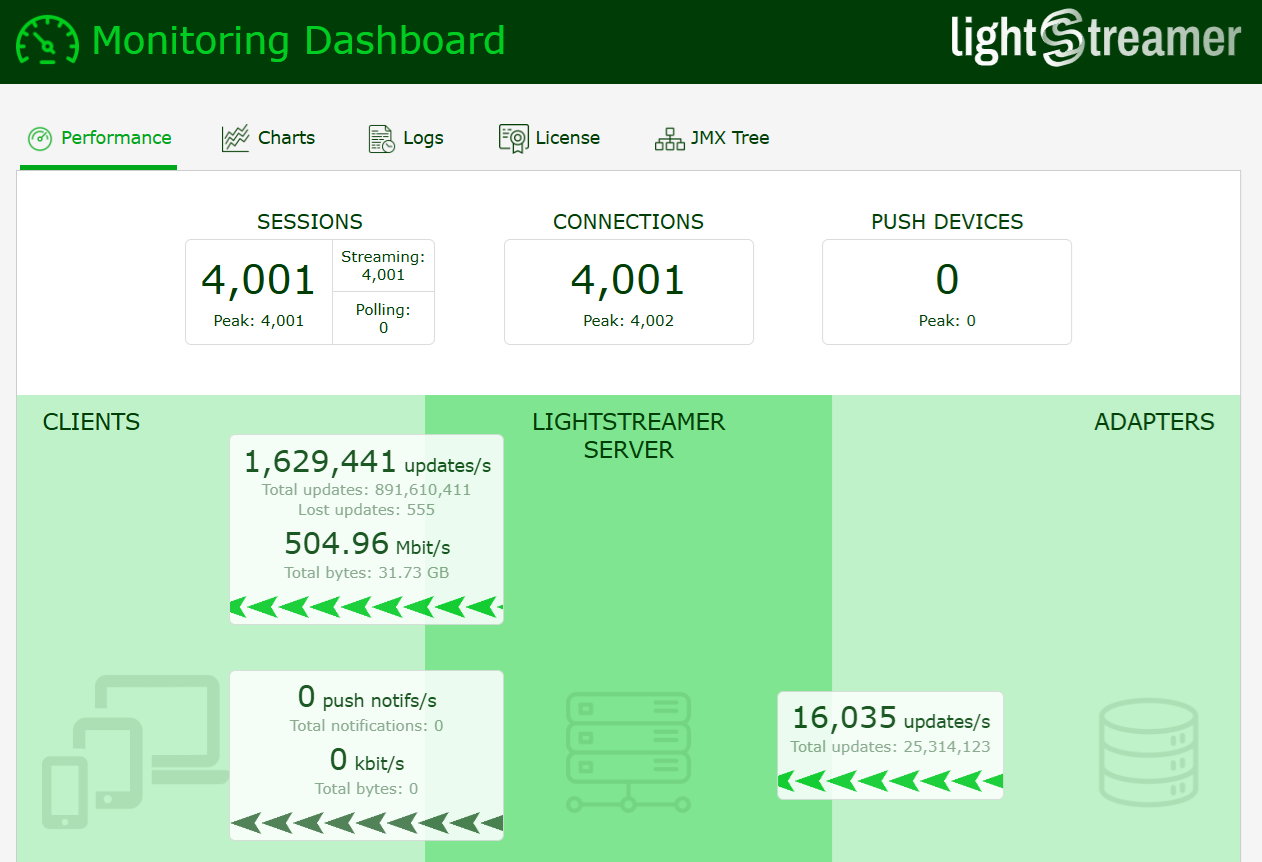
These results highlight the efficiency and scalability of the Lightstreamer Kafka Connector, demonstrating its ability to deliver high-throughput, low-latency streaming even in resource-constrained environments.
Test methodology
Setup the environment
The tests were conducted in an AWS environment using EC2 instances. Specifically, the following instances were dedicated:
- t2.small instance The primary purpose of this server is to measure message latencies. Latency is calculated for the entire journey, from the moment the message is generated by the producer to the moment it is consumed by the Lightstreamer client—passing through the Kafka broker and then the Lightstreamer broker. To achieve this, this instance runs the Lightstreamer client with the statistical calculations module enabled, along with a specialized version of the message producer. This producer generates a small number of messages, each including a timestamp as a prefix in a specific JSON field, indicating the exact moment the message was created. Since both the producer (generating timestamps) and the latency-calculating client reside on the same machine, clock synchronization issues were avoided.
- c7i.2xlarge instance This instance was dedicated to the Kafka broker.
- c7i.xlarge instance This instance was dedicated to Lightstreamer Kafka Connector.
- Multiple c7i.2xlarge instances These instances simulated clients. To simulate thousands of concurrent client connections, we used a modified version of the Lightstreamer Load Test Toolkit.
- Multiple c7i.2xlarge instances These instances were dedicated to generate the load of messages pushed to kafka, depending on the scenario of the running test a different parameter of the
MessageGeneratorwas triggered.
As the Kakfa broker we used the official Apache distribution version 3.9.0. For the installation simply follow the basic instructions from this tutorial: https://kafka.apache.org/quickstart
The Lightstreamer server version used was 7.4.5, and Lightstreamer Kafka Connector version was 1.2.0. To install these for the tests, start with the brief guide ‘GETTING_STARTED.TXT’ found in the default distribution of the Lightstreamer server. Next, install the LoadTestToolkit adapter as explained here. Finally, install Lightstreamer Kafka Connector.
The JVM used in all tests was the latest LTS available, spcifically: OpenJDK Runtime Environment Corretto-21.0.2.13.1 (build 21.0.2+13-LTS).
Basic Scenario
All tests were conducted using the load generation tools available in this GitHub project, https://github.com/Lightstreamer/lightstreamer-kafka-connector-loadtest, previously employed for a load testing session documented in this blog post.
Specifically, for the initial scenario, we utilized the JsonProducer.java class to generate and transmit messages with a key to Kafka. The message key could be either a standard string, such as a fruit name, or an extended string of up to 500 characters. We executed tests with both key modes, and the results presented are those obtained with the extended key, representing the higher computational load. The command to activate a generator producing 4,000 messages per second with the extended key is as follows:
java -cp "dependency/*" com.lightstreamer.MessageGenerator <kafka broker url>:9092 LTest002 100 25 1024 json false true > prod_001.txt &To collect results and calculate latencies, we utilize a small t2.small EC2 instance to run a message producer. This producer adds a unique identifier as a prefix to a specific field, enabling a dedicated client running on the same machine to recognize these messages and calculate their latencies. Below are the commands for both:
java -cp "dependency/*" com.lightstreamer.MessageGenerator <kafka broker url>:9092 LTest002 1 50 1024 json true true
java -cp "dependency/*" com.lightstreamer.LightstreamerConsumer --calculate-latency-stats --server-address=http://<lightstreamer server url>:8080 --extended-keyAnd the one reported below is the mapping configuration for the Lightstreamer Kafka Connector:
<!-- TOPIC MAPPING SECTION -->
<!-- Define a "ltest" item-template, which is composed of a prefix 'ltest-'
concatenated with a value among those possible for the message key.
For example: "ltest-[key=Apple]", "ltest-[key=Banana]",
"ltest-[key=Orange]. -->
<param name="item-template.ltest">ltest-#{key=KEY}</param>
<!-- Map the topic "LTest" to the previous defined "ltest" item template. -->
<param name="map.LTest002.to">item-template.ltest</param>
<!-- FIELDS MAPPING SECTION -->
<!-- Extraction of the record key mapped to the field "key". -->
<param name="field.key">#{KEY}</param>
<!-- Extraction of the JSON record value mapped to the field "value". -->
<param name="field.timestamp">#{VALUE.timestamp}</param>
<param name="field.fstValue">#{VALUE.fstValue}</param>
<param name="field.sndValue">#{VALUE.sndValue}</param>
<param name="field.intNum">#{VALUE.intNum}</param>
<!-- Extraction of the record timestamp to the field "ts". -->
<param name="field.ts">#{TIMESTAMP}</param>
<!-- Extraction of the record partition mapped to the field "partition". -->
<param name="field.partition">#{PARTITION}</param>
<!-- Extraction of the record offset mapped to the field "offset". -->
<param name="field.offset">#{OFFSET}</param>
Complex Structured JSON as the key of the message
For the scenario with a complex structured JSON used as the key of the messages pushed into kafka we utilized the JsonVeryComplexProducerWithJsonKey.java class to generate and transmit messages with serialized JSON object both for the key and body. The command to activate a generator producing 2,000 messages per second is as follows:
java -cp "dependency/*" com.lightstreamer.MessageGenerator ec2-3-250-205-114.eu-west-1.compute.amazonaws.com:9092 LTest001 100 50 1024 jsonkeyx false false > prova1.out &And these are the commands for the Lightstreamer client for statistics calculation and the special producer.
java -cp "dependency/*" com.lightstreamer.LightstreamerConsumer --calculate-latency-stats --server-address=http://ec2-63-35-178-85.eu-west-1.compute.amazonaws.com:8080 --kj
java -cp "dependency/*" com.lightstreamer.MessageGenerator ec2-3-250-205-114.eu-west-1.compute.amazonaws.com:9092 LTest001 1 50 1024 jsonkeyx true falseAnd the one reported below is the mapping configuration for the Lightstreamer Kafka Connector:
<!-- TOPIC MAPPING SECTION -->
<!-- Define a "ltest" item-template, which is composed of a prefix 'ltest-'
concatenated with a value among those possible for the message key.
For example: "ltest-[key=Apple]", "ltest-[key=Banana]",
"ltest-[key=Orange]. -->
<param name="item-template.ltest">ltest-#{key=KEY.names[998]}</param>
<!-- Map the topic "LTest" to the previous defined "ltest" item template. -->
<param name="map.LTest001.to">item-template.ltest</param>
<!-- FIELDS MAPPING SECTION -->
<!-- Extraction of the record key mapped to the field "key". -->
<param name="field.key">#{KEY.names[998]}</param>
<!-- Extraction of the JSON record value mapped to the field "value". -->
<param name="field.timestamp">#{VALUE.timestamp}</param>
<param name="field.firstText">#{VALUE.firstText}</param>
<param name="field.secondText">#{VALUE.secondText}</param>
<param name="field.thirdText">#{VALUE.thirdText}</param>
<param name="field.fourthText">#{VALUE.fourthText}</param>
<param name="field.firstnumber">#{VALUE.firstnumber}</param>
<param name="field.secondNumber">#{VALUE.secondNumber}</param>
<param name="field.thirdNumber">#{VALUE.thirdNumber}</param>
<param name="field.fourthNumber">#{VALUE.fourthNumber}</param>
<param name="field.hobbie0">#{VALUE.hobbies[0]}</param>
<param name="field.hobbie1">#{VALUE.hobbies[1]}</param>
<param name="field.names1">#{KEY.names[1]}</param>
<param name="field.names2">#{KEY.names[2]}</param>
<param name="field.names3">#{KEY.names[3]}</param>
<param name="field.names4">#{KEY.names[4]}</param>
<param name="field.names5">#{KEY.names[5]}</param>
<param name="field.names6">#{KEY.names[6]}</param>
<param name="field.names7">#{KEY.names[7]}</param>
<param name="field.names8">#{KEY.names[8]}</param>
<param name="field.names9">#{KEY.names[9]}</param>
<param name="field.names10">#{KEY.names[10]}</param>
<param name="field.names11">#{KEY.names[11]}</param>
<param name="field.names12">#{KEY.names[12]}</param>
...The client subscribes to the following item
String[] items_kj = { "ltest-[key=Timothy]" };Overall test
For the final comprehensive test, we essentially replicated the base scenario using the same tools described earlier. However, in this phase, we added a significant load to the Lightstreamer broker by introducing a high number of concurrent clients. To support this part of the test, we utilized a modified version of the Lightstreamer – Load Test Toolkit, which can be found in this GitHub branch: https://github.com/Lightstreamer/load-test-toolkit/tree/lightstreamer-kafka-connector-benchmark
Final Thoughts
The results of these tests underscore the robustness and scalability of the Lightstreamer Kafka Connector, demonstrating its ability to efficiently manage high-throughput message filtering with consistently low latency. Whether dealing with straightforward or computationally intensive filtering scenarios, the connector delivers reliable real-time performance while making optimal use of system resources.
Importantly, these tests were conducted using a relatively modest EC2 instance for the Lightstreamer server, specifically a c7i.xlarge with 4 cores and 8GiB of RAM. Despite this, the system handled demanding loads with impressive stability. Based on these results, we anticipate near-linear vertical scalability when moving to more powerful machines, ensuring sustained efficiency and responsiveness even under significantly heavier workloads.
These tests are intended to complement the earlier benchmarking efforts described in this previous blog post, which focused on scalability in terms of handling large numbers of concurrent clients — especially in comparison to clients connecting directly to a Kafka broker. While those tests highlighted the advantages of Lightstreamer in managing high client concurrency, this new round of testing emphasizes the connector’s ability to filter from extremely high-throughput Kafka topics. Together, they provide a comprehensive picture of the Lightstreamer Kafka Connector’s versatility and performance across a wide range of real-world production scenarios.




